ClickHouse, Druid и Pinot – три открытых хранилища данных, которые позволяют выполнять аналитические запросы на больших объемах данных с интерактивными задержками. Эта статья - перевод подробного сравнения, выполненного Романом Левентовым.
Подробности реализации ClickHouse стали мне известны от Алексея Зателепина, одного из ключевых разработчиков проекта. Доступная на английском документация достаточно скудна – наилучшим источником информации служат последние четыре секции данной страницы документации.
Я сам участвую в развитии Druid, но у меня нет личной заинтересованности в этой системе - по правде говоря, скорее всего в ближайшее время я перестану заниматься её разработкой. Поэтому читатели могут рассчитывать на отсутствие какой-либо предвзятости.
Всё, что я буду далее писать про Pinot, основывается на странице Архитектура в вики Pinot, а также на других страницах вики в разделе “Проектная документация”. Последний раз они обновлялись в июне 2017 года - больше, чем полгода назад.
Рецензентами оригинальной статьи стали Алексей Зателепин и Виталий Людвиченко (разработчики ClickHouse), Жан Мерлино (самый активный разработчик Druid), Кишор Гопалакришна (архитектор Pinot) и Жан-Француа Им (разработчик Pinot). Мы присоединяемся к благодарности автора и полагаем, что это многократно повышает авторитетность статьи.
Предупреждение: статья достаточно большая, поэтому вполне возможно вы захотите ограничиться прочтением раздела “Заключение” в конце.
На фундаментальном уровне, ClickHouse, Druid и Pinot похожи, поскольку они хранят данные и выполняют обработку запросов на одних и тех же узлах, уходя от “разъединенной” архитектуры BigQuery. Недавно я уже описывал несколько наследственных проблем со связанной архитектурой в случае Druid [1, 2]. Открытого эквивалента для BigQuery на данный момент не существует (за исключением, разве что, Drill?) Возможным подходам к построению подобных открытых систем посвящена другая статье в моем блоге.
Разработчики ClickHouse в Yandex планируют начать поддерживать обновления и удаления в будущем, но я не уверен, будут ли это “настоящие” точечные запросы или обновления/удаления диапазонов данных.
Это плавно подводит нас к следующему важному разделу.
Такой подход мне кажется неправильным, по крайней мере он неприменим в отношении открытых OLAP-систем для Big Data. Задача создания системы Bid Data OLAP, которая смогла бы работать эффективно в большинстве сценариев использования и содержала бы все необходимые функции настолько велика, что я оцениваю ее реализацию как минимум в 100 человеко-лет.
На сегодня, ClickHouse, Druid и Pinot оптимизированы только для конкретных сценариев использования, которые требуются их разработчиком - и содержат по большей части лишь те функции, в которых нуждаются сами разработчики. Я могу гарантировать, что ваш случай обязательно “упрется” в те узкие места, с которыми разработчики рассматриваемых OLAP-систем еще не сталкивались - или же в те места, что их не интересуют.
Не говоря уже о том, что упомянутый выше подход “забросить данные в систему, о которой вы ничего не знаете, и затем измерить её эффективность” весьма вероятно даст искаженный результат из-за серьезных “узких” мест, которые на самом деле могли бы быть исправлены простым изменением конфигурации, схемы данных или другим построением запроса.
Впрочем, я не стану спорить с их итоговым решением выбрать ClickHouse, поскольку на масштабе примерно в 10 узлов и для их нужд ClickHouse мне тоже кажется лучшим выбором, чем Druid. Но сделанное ими заключение о том, что ClickHouse как минимум на порядок эффективнее (по меркам стоимости инфраструктуры), чем Druid - это серьезное заблуждение. На самом деле, из рассматриваемых нами сегодня систем, Druid предлагает наилучшую возможность для реально дешевых установок (смотрите раздел “Уровни узлов обработки запросов в Druid ” ниже).
Когда вы выбираете систему OLAP Big Data, не сравнивайте то, насколько они сейчас хорошо подходят для вашего случая. Сейчас они все субоптимальны. Вместо этого, сравните, насколько быстро ваша компания способна заставить двигаться эти системы в том направлении, которое нужно именно вам.В силу своей фундаментальной архитектурной схожести, ClickHouse, Druid и Pinot имеют примерно один и тот же “предел” эффективности и оптимизации производительности. Здесь нет “волшебной таблетки”, которая позволила бы какой-либо из этих систем быть быстрее, чем остальные. Не позволяйте запутать себя тем фактом, что в своем текущем состоянии системы показывают себя очень по-разному в различных бенчмарках.
Допустим, Druid не поддерживает “сортировку по первичному ключу” настолько хорошо, насколько это умеет ClickHouse - а ClickHouse в свою очередь не поддерживает “инвертированные индексы” столь же хорошо, как Druid, что дает данным системам преимущества с той или иной нагрузкой. Упущенные оптимизации могут быть реализованы в выбранной системе при помощи не таких уж и больших усилий, если у вас есть намерение и возможность решиться на подобный шаг.
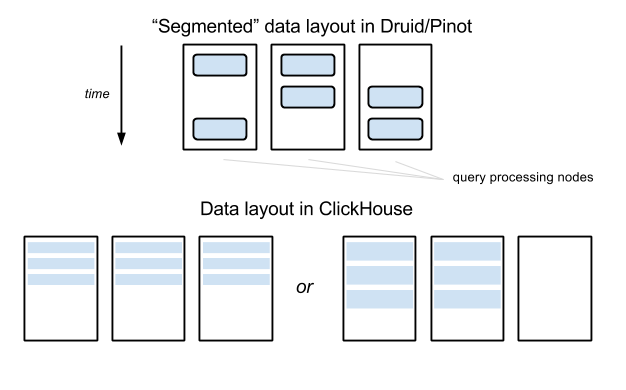
Сегменты хранятся в файловой системе хранилища «глубокого хранения» (например, HDFS) и могут быть загружены на узлы обработки запросов, но последние не отвечают за устойчивость сегментов, поэтому узлы обработки запросов могут быть заменены относительно свободно. Сегменты не привязаны жестко к конкретным узлам и могут быть загружены на те или другие узлы. Специальный выделенный сервер (который называется “координатором” в Druid и “контроллером” в Pinot, но я ниже обращаюсь к нему как к “мастеру”) отвечает за присвоение сегментов узлам, и перемещению сегментов между узлами, если потребуется.
Это не противоречит тому, что я отмечал выше, все три системы имеют статическое распределение данных между узлами, поскольку загрузки сегментов и их перемещения в Druid - и насколько я понимаю в Pinot - являются дорогими операциями и потому не выполняются для каждой отдельной очереди, а происходят обычно раз в несколько минут/часов/дней.
Метаданные сегментов хранятся в ZooKeeper - напрямую в случае Druid, и при помощи фреймворка Helix в Pinot. В Druid метаданные также хранятся в базе SQL, об этом будет подробнее в разделе “Различия между Druid и Pinot”.
В ClickHouse имеются секционированные таблицы, состоящие из указанного набора узлов. Здесь нет “центральной власти” или сервера метаданных. Все узлы, между которыми разделена та или иная таблица, содержат полные, идентичные копии метаданных, включая адреса всех остальных узлов, на которых хранятся секции этой таблицы.
Метаданные секционированной таблицы включают “весы” узлов для распределения свежезаписываемых данных - к примеру, 40% данных должны идти на узел A, 30% на узел B и 30% на C. Обычно же распределение должно происходить равномерно, “перекоос”, как в этом примере, требуется только тогда, когда к секционированной таблице добавляется новый узел и нужно побыстрее заполнить его какими-либо данными. Обновления этих “весов” должны выполняться вручную администраторами кластера ClickHouse, или же автоматизированной системой, построенной поверх ClickHouse.
Компромисс распределения данных в ClickHouse
В примере, показанном на изображении выше, данные таблицы распределены между тремя узлами в Druid/Pinot, но запрос по малому интервалу данных обычно затрагивает лишь два из них (до той поры, пока интервал не пересечет пограничный интервал сегмента). В ClickHouse, любые запросы будут вынуждены затронуть три узлв – если таблица сегментирована между тремя узлами. В данном примере разница не выглядит настолько существенно, однако представьте себе, что случится, если число узлов достигнет 100 – в то время как фактор сегментирования по-прежнему может быть равен, например, 10 в Druid/Pinot.
Чтобы смягчить эту проблему, самый большой кластер ClickHouse в Яндексе, состоящий из сотен узлов, в действительности разбит на многие «под-кластеры» с несколькими десятками узлов в каждом. Кластер ClickHouse используется в работе с аналитикой по веб-сайтам, и каждая точка данных имеет измерение «ID вебсайта». Существует жесткая привязка каждого ID сайта к конкретному под-кластеру, куда идут все данные для этого идентификатора сайта. Поверх кластера ClickHouse есть слой бизнес-логики, который управляет этим разделением данных при поглощении данных и выполнении запросов. К счастью, в их сценариях использования совсем немного запросов затрагивают несколько идентификаторов сайтов, и подобные запросы идут не от пользователей сервиса, поэтому у них нет жесткой привязки к реальному времени согласно соглашению об уровне услуг.
Другим недостатком подхода ClickHouse является то, что, когда кластер растет очень быстро, данные не могут перебалансироваться автоматически без участия человека, который вручную поменяет «веса» узлов в разбиваемой таблице.
Эта функция позволяет Metamarkets экономить сотни тысяч долларов расходов на инфраструктуру Druid каждый месяц - в противовес тому варианту, если бы использовался “плоский” кластер.
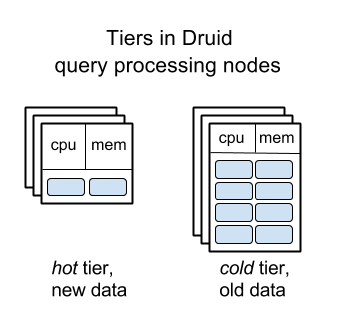
Уровни узлов обработки запросов в Druid
Насколько мне известно, в ClickHouse и Pinot пока еще нет похожей функциональности - предполагается, что все узлы в их кластерах одинаковы.
В силу того, что архитектура Pinot весьма схожа с архитектурой Druid, как мне кажется, будет не слишком сложно добавить аналогичную функцию в Pinot. Тяжелее будет в случае с ClickHouse, поскольку для реализации данной функции крайне полезно использование концепта “сегментов”, однако это всё равно возможно.
В самом большом кластере ClickHouse в Яндексе есть два одинаковых набора узлов в различных дата-центрах, и они спарены. В каждой паре узлы являются репликами друг друга (используется фактор репликации, равный двум), и они расположены в различных дата-центрах.
ClickHouse полагается на ZooKeeper для управления репликацией – поэтому, если вам не нужна репликация, то вам не нужен и ZooKeeper. Это означает, что ZooKeeper не потребуется и для ClickHouse, развернутого на одиночном узле.
Когда таблица может обновляться с задержкой в час или более, сегменты создаются при помощи движков пакетной обработки – к примеру, Hadoop или Spark. И в Druid, и в Pinot есть первоклассная поддержка Hadoop из коробки. Существует сторонний плагин для поддержки индексации Druid в Spark, но в данный момент официально он не поддерживается. Насколько мне известно, в Pinot такого уровня поддержки Spark пока нет, то есть вы должны быть готовы разобраться с интерфейсами Pinot и кодом, а затем самостоятельно написать код на Java/Scala, пусть это и не должно быть слишком сложно. (Впрочем, с момента публикации оригинальной статьи поддержка Spark в Pinot была внесена контрибьютором).
Когда таблица должна обновляться в реальном времени, здесь приходит на помощь идея “реалтаймовых» узлов, которые делают три вещи: принимает новые данные из Kafka (Druid поддерживает и другие источники), обслуживает запросы с недавними данными, создает сегменты в фоне и затем записывает их в “глубокое хранилище”.Если таблица разбита на сегменты, то узел, который принимает пакетную запись (например, 10к строк) распределяет данные согласно “весам” (смотрите раздел ниже). Строки записываются одним пакетом, который формирует небольшое “множество”. Множество немедленно конвертируется в колоночный формат. На каждом узле ClickHouse работает фоновый процесс, который объединяет наборы строк в еще большие наборы. Документация ClickHouse сильно завязана на принцип, известный как “MergeTree”, и подчеркивает схожесть его работы с LSM-деревом, хотя меня это слегка смущает, поскольку данные не организованы в деревья - они лежат в плоском колончатом формате.
Поглощение данных в ClickHouse гораздо проще (что компенсируется сложностью управления “историческими” данными - т.е. данными не в реальном времени), но и здесь есть один момент: вы должны иметь возможность собирать данные в пакеты до самого ClickHouse. Автоматическое поглощение и пакетный сбор данных из Kafka доступно “из коробки”, но если у вас используется другой источник данных в реальном времени (здесь подразумевается всё, что угодно, в диапазоне между инфраструктурой запросов, альтернативной Kafka, и стриминговых движков обработки, вплоть до различных HTTP-endpoint), то вам придется создать промежуточный сервис по сбору пакетов, или же внести код напрямую в ClickHouse.
Я не берусь предполагать, зачем при проектировании Druid и Pinot было принято решение о введении еще одного типа узлов. Однако, теперь они кажутся их неотъемлемой частью, поскольку, когда общее количество сегментов в кластере начинает превышать десять миллионов, информация об отображении сегментов в узлы начинает занимать гигабайты памяти. Это очень расточительно – выделять столько много памяти на каждом узле для обработки запросов. Вот вам и еще один недостаток, который накладывается на Druid и Pinot их «сегментированной» архитектурой управления данными.
В ClickHouse выделять отдельный набор узлов под “брокер запросов” обычно не требуется. Существует специальный, эфемерный “распределенный” тип таблицы в ClickHouse, который может быть установлен на любом узле, и запросы к этой таблице будут делать все то же, за что отвечают брокер-узлы в Druid и Pinot. Обычно подобные эфемерные таблицы размещаются на каждом узле, который участвует в секционированной таблице, так что на практике каждый узел может быть “входной точкой” для запроса в кластер ClickHouse. Этот узел может выпускать необходимые подзапросы к другим секциями, обрабатывать свою часть запроса самостоятельно и затем объединять её с частичными результатами от других секций.
Когда узел (или один из процессинговых узлов в ClickHouse, или брокер-узел в Druid и Pinot) выпускает подзапросы к другим, и один или несколько подзапросов по какой-либо причине заканчиваются неудачей, ClickHouse и Pinot обрабатывают эту ситуацию правильно: они объединяют результаты успешно выполненных подзапросов вместе, и всё равно возвращают частичный результат пользователю. Druid этой функции сейчас очень недостает: если в нем выполнение подзапроса заканчивается неудачей, то неудачей закончится и весь запрос целиком.
ClickHouse похож на традиционные RDMBS, например, PostgreSQL. В частности, ClickHouse можно развернуть на всего один сервер. Если планируемый размер невелик - скажем, не больше порядка 100 ядер CPU для обработки запросов и 1 TB данных, я бы сказал, что ClickHouse имеет значительные преимущества перед Druid и Pinot в силу своей простоты и отсутствия необходимости в дополнительных типах узлов, таких как “мастер”, “узлы поглощения в реальном времени”, “брокеры”. На этом поле, ClickHouse соревнуется скорее с InfluxDB, чем с Druid или Pinot.
Druid and Pinot похож на системы Big Data вроде HBase. Здесь в виду имеются не характеристики производительности, а зависимость от ZooKeper, зависимость от персистентного реплицируемого хранилища (к примеру, HDFS), сосредоточение внимания на устойчивости к отказам отдельных узлов, а также автономная работа и управление данными, не требующими постоянного внимания человека.
Для широкого спектра приложений, ни ClickHouse, ни Druid или Pinot не являются очевидными победителями. В первую очередь, вы должны принимать во внимание вашу способность разобраться с исходным кодом системы, исправлять баги, добавлять новые функции и т.д. Это подробнее обсуждается в разделе “Про сравнение производительности и выбор системы”.
Во-вторых, вам стоит взглянуть на таблицу ниже. Каждая ячейка в этой таблице описывает свойство приложения, которое позволит определить предпочтительную систему. Строки отсортированы не в порядке важности. Важность различных свойств может разниться от приложения к приложению, но в целом можно применить следующий подход: если ваше приложение соответствует подавляющему большинству строк со свойствами в одной из колонок, то относящаяся к ней система в вашем случае является предпочтительным выбором.
| ClickHouse | Druid или Pinot |
|---|---|
| В организации есть эксперты по C++ | В организации есть эксперты по Java |
| Малый кластер | Большой кластер |
| Немного таблиц | Много таблиц |
| Один набор данных | Несколько несвязанных наборов данных |
| Таблицы и данные находятся в кластере перманентно | Таблицы и наборы данных периодически появляются в кластере и удаляются из него |
| Размер таблиц (и интенсивность запросов к ним) остается стабильным во времени | Таблицы значительно растут и сжимаются |
| Однородные запросы (их тип, размер, распределение по времени суток и т.д.) | Разнородные запросы |
| В данных есть измерение, по которому оно может быть сегментировано, и почти не выполняется запросов, которые затрагивают данные, расположенные в нескольких сегментах | Подобного измерения нет, и запросы часто затрагивают данные, расположенные во всем кластере |
| Облако не используется, кластер должен быть развернут на специфическую конфигурацию физических серверов | Кластер развернут в облаке |
| Нет существующих кластеров Hadoop или Spark | Кластеры Hadoop или Spark уже существуют и могут быть использованы |
Примечание: ни одно из свойств выше не означает, что вы должны использовать соответствующую систему (системы), или избегать другую. К примеру, если планируется, что ваш кластер будет большим, это не значит, что вы обязательно должны рассматривать только Druid или Pinot, исключив ClickHouse. Скорее всего, в данной ситуации Druid или Pinot могут быть лучшим выбором, но другие полезные свойства могут перевесить чашу весов в сторону ClickHouse, который для некоторых приложений является оптимальным выбором даже для больших кластеров.
Между Druid и Pinot существует лишь одно существенное различие, которое слишком велико для того, чтобы от него избавились в обозримом будущем - это реализация управления сегментами в мастер-ноде. Кстати, разработчики обеих систем наверняка не хотели бы этого делать в любом случае, поскольку оба подхода имеют свои “за” и “против” - среди них нет такого, который был бы лучше.
С одной стороны, я могу понять, что это дает разработчикам Pinot возможность сосредоточиться на других частях их системы. В Helix возможно меньше багов, чем в логике внутри самого Druid, поскольку он тестируется в других условиях и поскольку в него, предположительно, было вложено гораздо больше рабочего времени.
С другой стороны, Helix возможно ограничивает Pinot своими “рамками фреймворка”. Helix, и следовательно, Pinot, скорее всего будут зависеть от ZooKeeper всегда.
Далее я собираюсь перечислить менее важные различия между Druid и Pinot - в том смысле, что если у вас возникнет серьезное желание повторить одну из этих функций в вашей системе, то это будет вполне осуществимо.
Эта концепция в оригинале называется “predicate pushdown” и важна для поддержания высокой производительности в некоторых приложениях.
На данный момент Druid поддерживает разбиение по ключам, если сегменты были созданы в Hadoop, но еще не поддерживает сегменты, созданные во время поглощения в реальном времени. Druid сейчас не реализует функцию «проталкивания предикатов» на брокеры.
К сожалению Uber по большей части использовал запросы count (*) для сравнения производительности Druid и Pinot относительно выполнения запроса [1, 2], который сейчас в Druid представляет собой тупое линейное сканирование, хотя его и несложно заменить корректной O(1) реализацией. Это вам еще один пример бессмысленных сравнений в стиле “черного ящика”, о которых мы говорили ранее.
По моему мнению, причины сильного различия в производительности запросов GROUP BY, которое наблюдали в Uber, стоит искать в недостатке сортировки данных в сегментах Druid, как уже было отмечено выше в этом разделе.Не знаю, как в LinkedIn управляются со всем при помощи настолько простого алгоритма балансировки сегментов в Pinot, но, вполне возможно, их ожидают значительные улучшения по части производительности, если они решатся потратить время на совершенствование используемого ими алгоритма.
В Druid такой функции на данный момент.
Насколько мне известно, в Pinot на данный момент аналогичная функциональность отсутствует.
В силу схожести архитектур, ClickHouse, Druid и Pinot имеют примерно одинаковый “предел оптимизации”. Но в своем текущем состоянии, все три системы еще незрелы и очень далеки от этого лимита. Существенных улучшений в производительности данных систем (применительно к специфическим сценариям использования) можно достичь несколькими человеко-месяцами работы опытных инженеров.
Я бы не рекомендовал вам сравнивать производительность данных систем между собой - выберите для себя ту, чей исходный код вы способны понять и модифицировать, или ту, в которую вы хотите инвестировать свои ресурсы.Из этих трех систем, ClickHouse стоит немного в стороне от Druid и Pinot - в то время как Druid и Pinot практически идентичны, и их можно считать двумя независимо разрабатываемыми реализациями одной и той же системы.
ClickHouse больше напоминает “традиционные” базы данных вроде PostgreSQL. ClickHouse можно установить на один узел. При малых масштабах (менее 1 TB памяти, менее 100 ядер CPU), ClickHouse выглядит гораздо более интересным вариантом, чем Druid или Pinot - если вам все еще хочется их сравнивать - в силу того, что ClickHouse проще и имеет меньше движущихся частей и сервисов. Я бы даже сказал, что на таком масштабе он скорее становится конкурентом для InfluxDB или Prometheus, а не для Druid или Pinot.
Druid и Pinot больше напоминают другие системы Big Data из экосистемы Hadoop. Они сохраняют свои “самоуправляемые” свойства даже на очень больших масштабах (более 500 узлов), в то время как ClickHouse потребует для этого достаточно много работы профессиональных SRE. Кроме того, Druid и Pinot занимают выигрышную позицию в плане оптимизации инфраструктурной стоимости больших кластеров, и лучше подходят для облачных окружений, чем ClickHouse.
Единственным долгосрочным различием между Druid и Pinot является то, что Pinot зависит от фреймворка Helix и будет продолжать зависеть от ZooKeeper, в то время как Druid может уйти от зависимости от ZooKeeper. С другой стороны, установка Druid продолжит зависеть от наличия какой-либо SQL-базы данных. На данный момент, Pinot оптимизирован лучше, чем Druid.
Если вы уже сталкивались с необходимостью сравнения этих систем и сделали свой выбор, то приходите на одну из наших конференций и расскажите о своем кейсе: о том какие именно были задачи и какие грабли (а наверняка они были) вы встретили. Хотя, конечно, базы данных далеко не единственная тема. Ближайший по окончанию срока подачи заявок (до 9 апреля) фестиваль РИТ++ включает направления: фронтенд, бэкенд, эксплуатацию и управление. Участникам обычно интереснее всего узнать о конкретных примерах, но и выступления и в виде обзоров и исследований тоже возможны – главное, чтобы тема была интересна лично вам.